Traduciendo decisiones al entorno digital
# Introdución
En este breve artículo abordaremos CXDP, un proyecto de investigación interno donde estudiamos cómo podemos mejorar el desarrollo de herramientas comerciales internas centrándonos en la interacción entre expertos de dominio y equipos de tecnología. En la primera etapa del proyecto, entrevistamos a profesionales que trabajan en startups de biotecnología, grandes consultoras y empresas de comercio electrónico en Estados Unidos y América Latina. Nuestro objetivo era comprender cómo se pueden integrar los criterios humanos en las tareas digitales a través de una experiencia digital low-code.
El sesgo humano en la toma de decisiones tiende a considerarse un tema relevante, o al menos en los campos de la psicología conductual y las ciencias cognitivas. En la vida normal, las decisiones se toman en base a múltiples factores que a veces no reconocemos conscientemente, ya sea parte de nuestra rutina diaria o una reacción a un factor externo (como esquivar a un mal conductor).
Cuando nos referimos a sesgo no pretendemos asignarle el significado que lo limita a la tendencia negativa que puede tener un sujeto hacia determinado criterio o interpretación, sino reconocer que el sesgo a veces es necesariamente bueno. Evitando profundizar en trabajos específicos, como los propuestos por Tversky y Kahnneman, podemos referirnos al concepto de heurística, aquellas reglas o criterios que proporcionan un contexto al sujeto que facilita la interpretación de la información que recibe, como también la realización de tareas. En pocas palabras, son atajos para facilitar la solución de un problema.
Ahora, consideremos otro concepto, la idea de un experto en un determinado campo de conocimiento. Aunque las escuelas de pensamiento críticas y socráticas se opondrían a nuestra afirmación de la capacidad de ser verdaderamente un experto, la sociedad generalmente atribuye a algunos individuos la calificación de “experto” para señalar que tienen conocimientos sumamente buenos sobre un tema determinado.
Si tomamos estos conceptos en nuestro espectro, podríamos suponer que los expertos tienen algunas reglas heurísticas y criterios que necesariamente ayudan o mejoran la toma de decisiones en los campos de su dominio. Autores como Nassim Taleb no estarían de acuerdo, al menos en un grado moderado, argumentando que hay suficiente evidencia de criterio experto alejado de la realidad de los hechos, resultando incluso perjudicial para la posibilidad de anticipar o resolver adecuadamente los problemas propuestos.
Por lo que nos importa en este proyecto, no tomaremos en consideración decisiones destinadas a pronosticar eventos, centrándonos en aquellos dominios del conocimiento en los que los expertos facilitan la interpretación de la información. Por ejemplo, a pesar de cualquier negacionismo experto que podamos promover, probablemente estaríamos de acuerdo en que construir un puente con un ingeniero es mejor que hacerlo con un piloto de línea aérea o un abogado (definitivamente colocaremos al piloto en segundo lugar).
Este es el caso de los algoritmos genéticos aplicados a la psiquiatría clínica, ya que también requieren de la intervención de expertos preparados para diagnosticar los síntomas, junto con los perfiles genéticos, de una determinada condición (bipolar, depresión, etc.). Otro ejemplo podrían ser las prácticas AML (Anti Money Laundering), donde los abogados establecen y afinan los criterios para juzgar determinadas operaciones como sospechosas, o los corredores de seguros que analizan su grupo de clientes para minimizar el riesgo global de la cartera (o ajustar precio de acuerdo con el mismo).
Teniendo en cuenta estas intervenciones de expertos, nos embarcamos en el desarrollo de una herramienta de creación de reglas basada tanto en lógica proposicional como en lenguajes de programación SQL (lenguaje de consulta estructurado).
Nuestro objetivo fue crear el prototipo de un sistema de elaboración de reglas que permita a los expertos sin conocimiento de software poner sus criterios a disposición de los desarrolladores, lo que convencionalmente podría denominarse como una aplicación “low-code” o “no-code”.
# Determinando el contexto
Como enfoque principal, queríamos facilitar el proceso mediante el cual los expertos en el dominio brindan comentarios a los desarrolladores, al mismo tiempo que les permitimos compartir su conocimiento en un formato fácilmente disponible.
Al principio, nos centramos tanto en el método mediante el cual se implementarían las reglas como en la forma en que podrían hacerse accesibles. En cuanto a la implementación, creamos una aplicación web que contiene formularios en los que se pueden crear proposiciones de manera similar a reglas lógicas.
Para permitir a los usuarios crear colecciones de reglas, deben primero generar las propiedades para los casos en los que se aplicarán. Por ejemplo, si vamos a determinar qué genes y comportamientos deben indicar una determinada condición, debemos determinar las propiedades (fenotipo del gen, comportamientos observados, etc.), determinar si están presentes (valores booleanos) y luego establecer qué condición corresponde al caso evaluado (valores de retorno).
Para facilitar nuestro ejemplo, veamos cómo se construiría una colección de reglas:
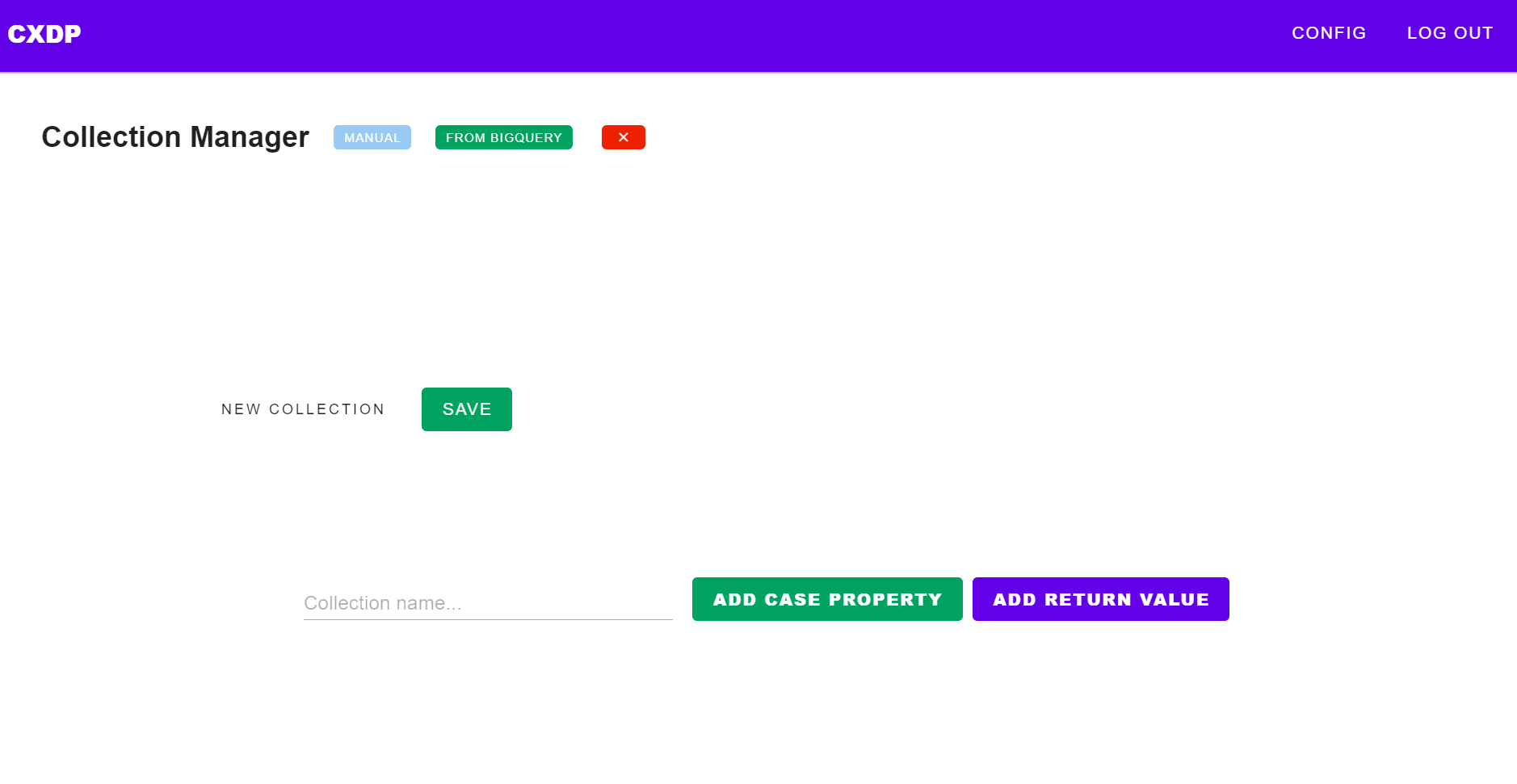
Para permitir a los usuarios crear sus reglas, primero deben establecer un nombre para la colección, llamémoslo "algoritmo genético" o GEN-ALGO.

Después de nombrar, tenemos que establecer qué propiedades van a ser las que consideraremos para nuestros casos. Para simplificarlo, podríamos utilizar genes con sus correspondientes variaciones y síntomas o conductas que observemos en los pacientes.

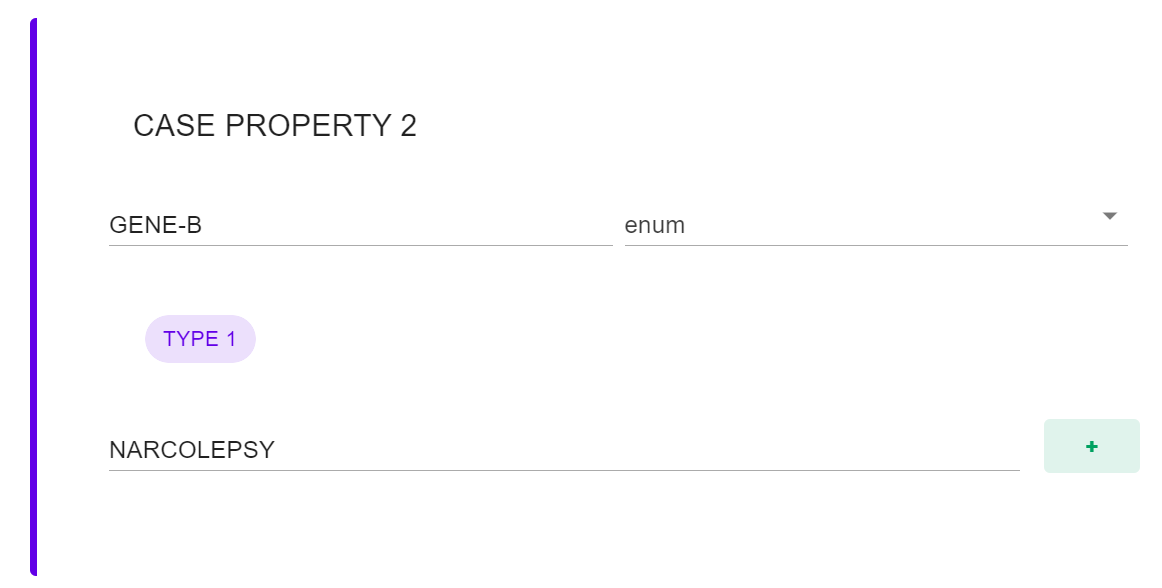

Recordemos que no estamos haciendo una revisión exhaustiva de la psiquiatría clínica, solo estamos ejemplificando cómo una práctica específica podría traducirse en una aplicación digital.
Una vez determinadas las propiedades del caso, debemos establecer cuáles son los valores de retorno que queremos para aquellos casos que cumplan con nuestras propiedades determinadas.

En nuestro caso teórico, ahora tenemos un esquema con propiedades en el que juzgaremos los casos que contengan las propiedades establecidas y, dadas las condiciones que estableceremos en las reglas, tendremos valores de retorno determinados.
# Haciendo reglas
Luego de definir el entorno en el que se tendrán que tomar nuestras decisiones, comenzamos por realizar las reglas específicas que proporcionarán un valor de retorno determinado según esos casos.
Para nuestro propósito general, cualquier regla dentro de un esquema se construye con los mismos componentes básicos. Creamos las reglas generando la lógica detrás de cómo examinaríamos o resolveríamos un caso determinado. En lógica proposicional, podríamos proponer que si se da una condición, o dos, entonces podemos inferir una consecuencia.
Un ejemplo de estas afirmaciones lógicas sería:
Si p entonces q
p → q
Si p y q entonces r
(p ∧ q) → r
El procesamiento de la información está estrechamente relacionado con el pensamiento lógico, aunque supone un gran obstáculo transferir adecuadamente los criterios utilizados al evaluar las condiciones que devienen en determinados resultados.
Dadas las dificultades que surgen con enunciados complejos en lógica proposicional, intentamos facilitar las proposiciones principales implementando elementos estándar y enunciados condicionales.

Para entenderlos, proponemos partir de un ejemplo que es una declaración básica SI - ENTONCES. Esta declaración afirmará que dadas ciertas condiciones, se deberá devolver un determinado valor.
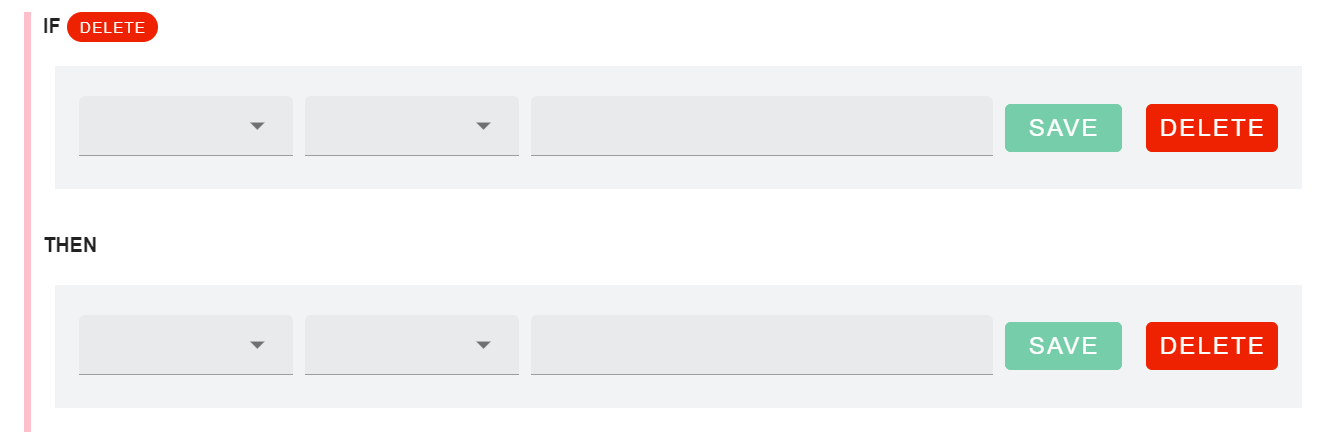
p → q
La declaración IF GROUP proporciona un cúmulo de IF THEN, lo que permite al usuario realizar una concatenación de condiciones. Luego, todos estos pueden someterse a los condicionales Y/O, lo que amplifica el espectro de reglas.
En este caso, al ser la variable un tipo de datos ENUMERATE, asignamos la condición ES o NO ES (booleana) y luego el tipo de condición dentro de la variable que esperamos.
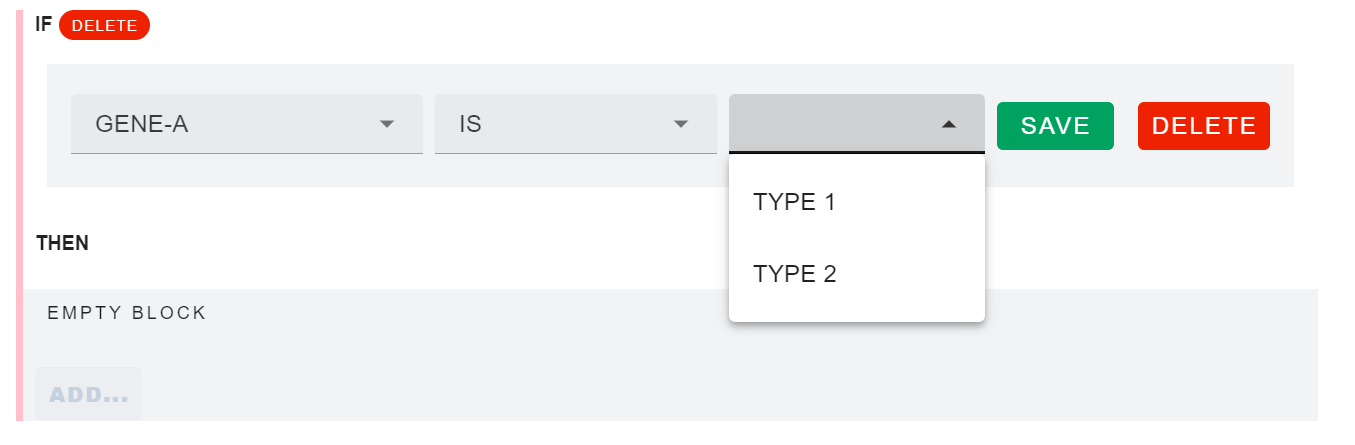
En nuestro ejemplo seleccionaremos el GEN A para que sea Tipo 1 y luego estableceremos la siguiente condición, que terminará en una tautología, en la que diremos que entonces no es tipo 2. Esto es básicamente decir lo mismo dos veces.
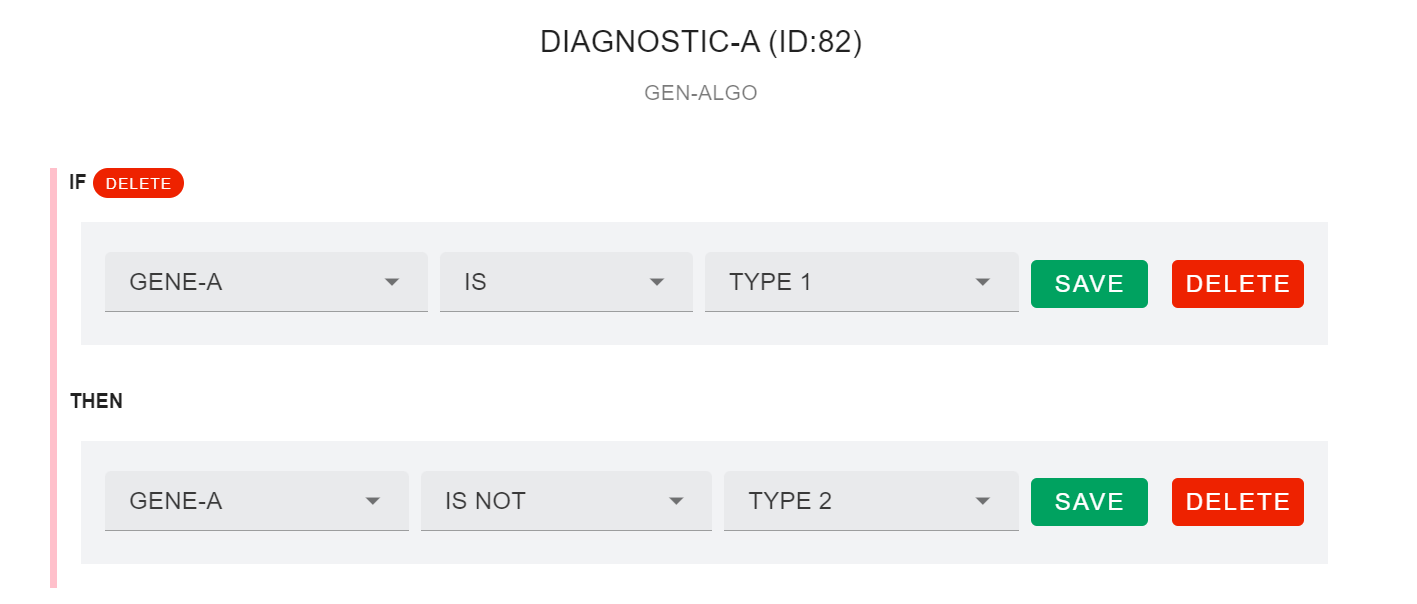
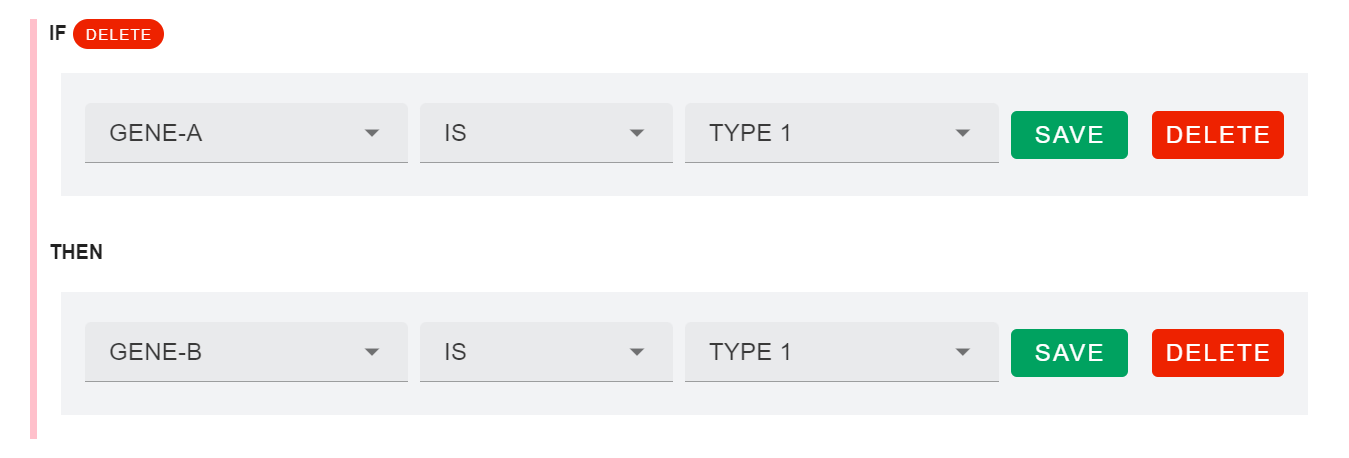
También podríamos establecer otra condición por la cual el valor de retorno sea la afirmación de que otro fenotipo genético debe ser de un determinado tipo.
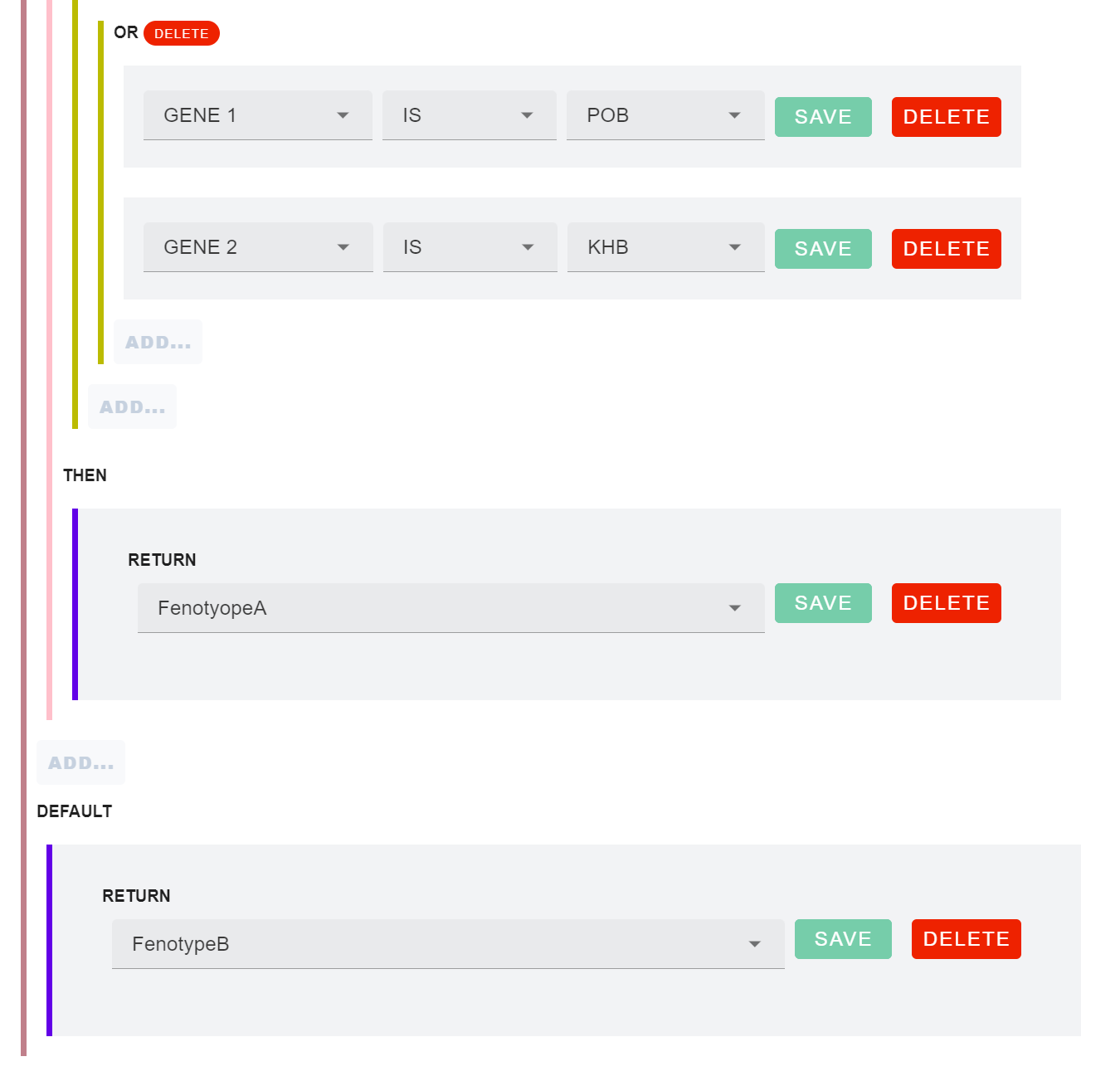
Veamos cómo podría verse una declaración combinada y más extensa para determinar un fenotipo. En este caso, indicaremos que si se dan 3 condiciones juntas, o una sola, entonces debería devolver FenotipoA, devolviendo por defecto FenotipoB. Esto concluye que la condición general es el Fenotipo B, siendo que deben darse ciertas condiciones para que esa propiedad cambie.

La cantidad de reglas e información que podemos procesar depende principalmente del conjunto de datos al que aplicamos nuestros criterios. Si tenemos sólo dos propiedades para diez casos, entonces tomarnos la molestia de construir reglas puede no estar justificado, ya que podemos contar fácilmente con los dedos aquellos casos que se aplican a nuestros criterios.
Ahora bien, si quisiéramos evaluar diez millones de peticiones de seguros de acuerdo con treinta variables para cada una de ellas, y al mismo tiempo agruparlas en determinados grupos, entonces establecer criterios generales facilitaría definitivamente el proceso.
Para que los resultados sean fácilmente accesibles brindamos un análisis muy elemental al usuario, generando una pestaña de resultados para ver cómo se han aplicado las reglas al conjunto de datos proporcionado. Esto se puede mostrar como una tabla o como un gráfico de barras.
Tabla de resultados
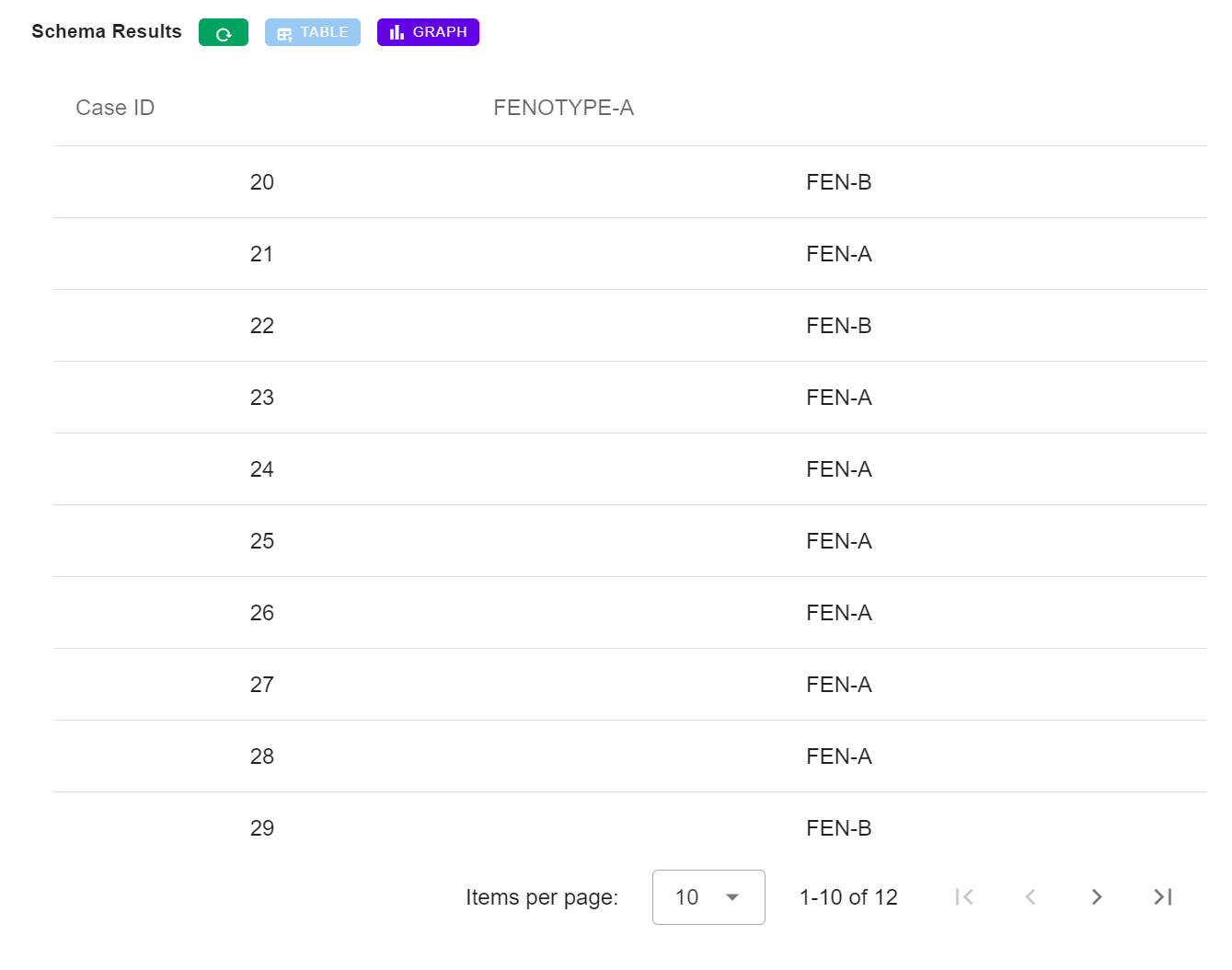
Gráfico de barras de resultados
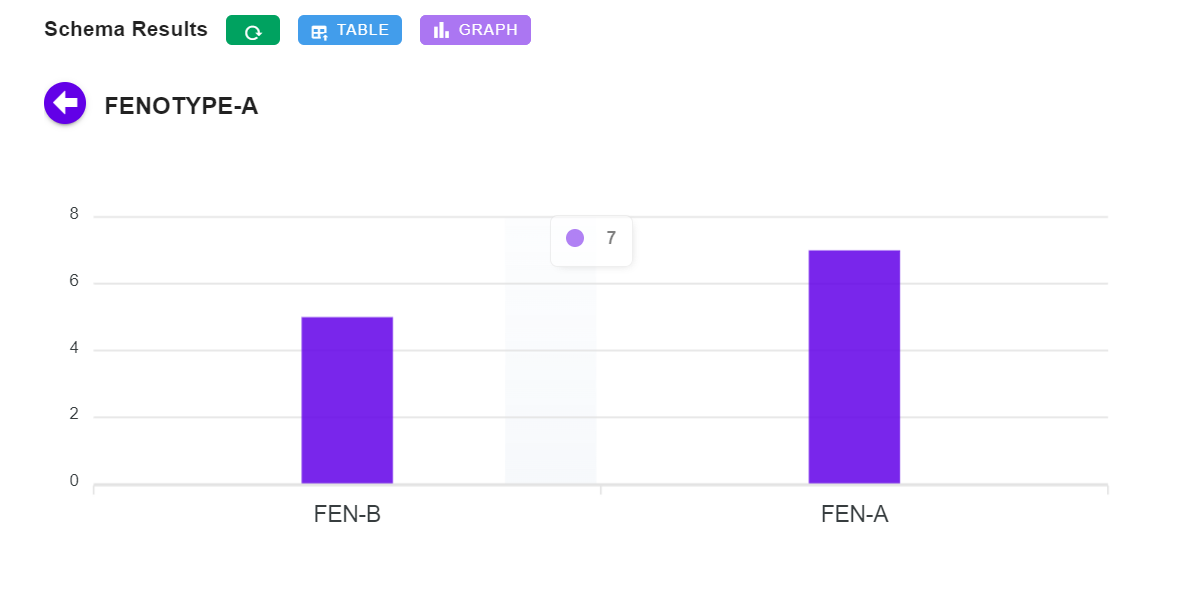
Nuestro objetivo no es crear una vista integrada de Business Intelligence, sino proporcionar a los creadores de reglas una vista previa sobre la distribución de los criterios que establecen para los datos que están modelando. Esto luego se puede exportar a través de la API a aplicaciones de BI más sofisticadas.
# Accesibilidad para desarrolladores
Aunque existen otros componentes para los usuarios, centrémonos en aquellas funcionalidades que facilitan la accesibilidad al núcleo de la herramienta. Al igual que con cualquier plataforma digital moderna, hemos incluido una API enriquecida en CXDP que permite a los desarrolladores realizar mediante consultas cualquier acción que se puede realizar en la interfaz de usuario.
El concepto clave que queríamos promover con CXDP es la idea de que usuarios no técnicos administren reglas lógicas específicas del dominio y un motor API que pueda invocar las reglas para servir a los equipos técnicos. Después de encuestar a desarrolladores y analistas de diferentes empresas financieras y de comercio electrónico, nos dimos cuenta de que la aplicación de la lógica basada en reglas a escala se realiza de dos maneras diferentes: sobre la marcha y por lotes.
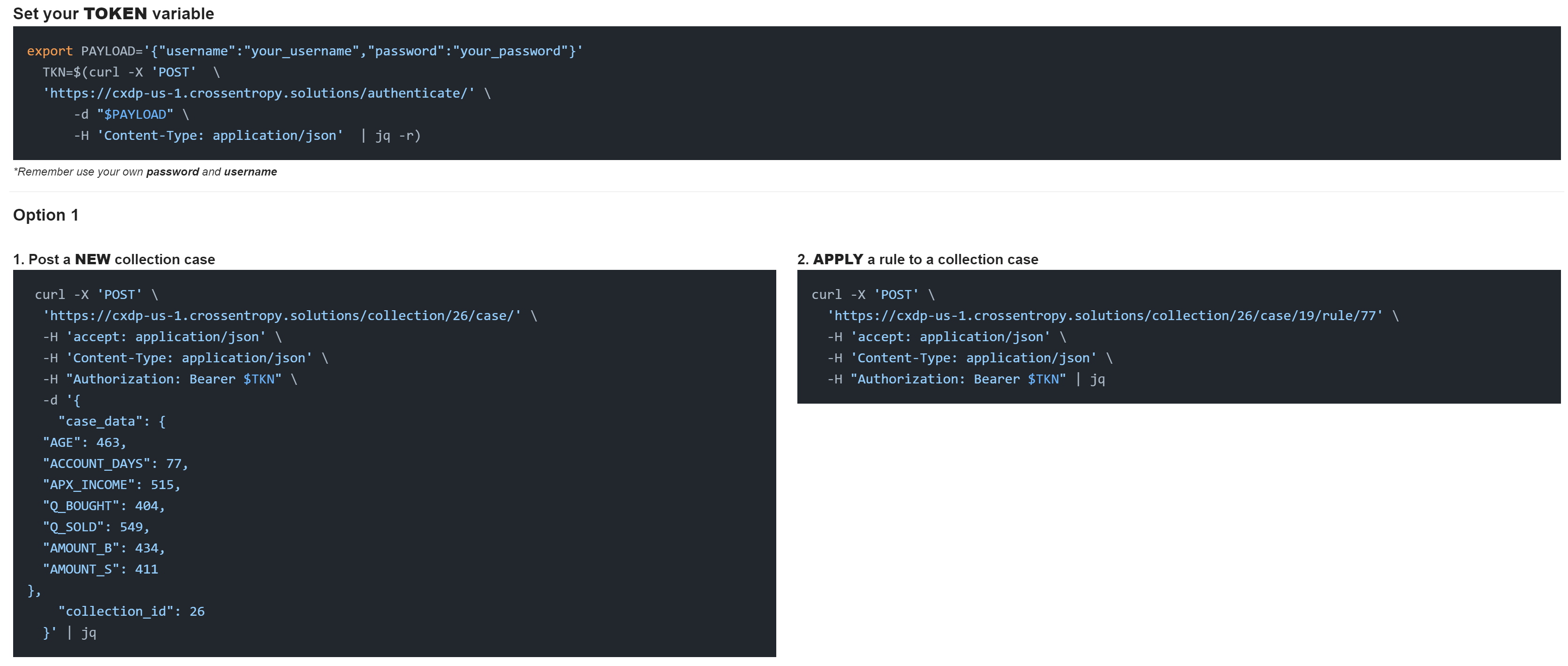
Las solicitudes sobre la marcha en CXDP son solicitudes HTTP realizadas por un sistema externo para aplicar una serie de decisiones a un caso. El motor API aplicará las decisiones diseñadas por los analistas a cualquier dato que se envíe a CXDP y produzca una respuesta que sea consumida por el cliente http. Un ejemplo de solicitudes sobre la marcha sería un sistema de crédito automatizado que aprueba préstamos mediante programación, conectando la interfaz de usuario web de una aplicación al conjunto de reglas creadas por el departamento de aprobaciones.
En cuanto a las solicitudes por lotes, este sería el caso de reglas que deben aplicarse a muchas filas de datos a escala. En este escenario, aplicamos nuestra lógica y reglas de casos a SQL, para lo cual hemos creado una integración con Google Big Query para permitir cargas de trabajo a escala de petabytes. Cualquier regla que se pueda aplicar a un caso de datos sobre la marcha se puede aplicar a millones de filas mediante el procesamiento por lotes.
Para mayor flexibilidad, definimos un sistema de representación interna basado libremente en JsonLogic que nos permite compilar sin problemas nuestras reglas en diferentes sistemas.
Para solicitudes por lotes, convertimos nuestra representación interna a BigQuery SQL e interactuamos con Google Cloud para administrar la aplicación de reglas a escala. Cuando se proporciona el proyecto y el ID del conjunto de datos, aplicamos la regla SQL directamente sobre los datos almacenados en Google Cloud.
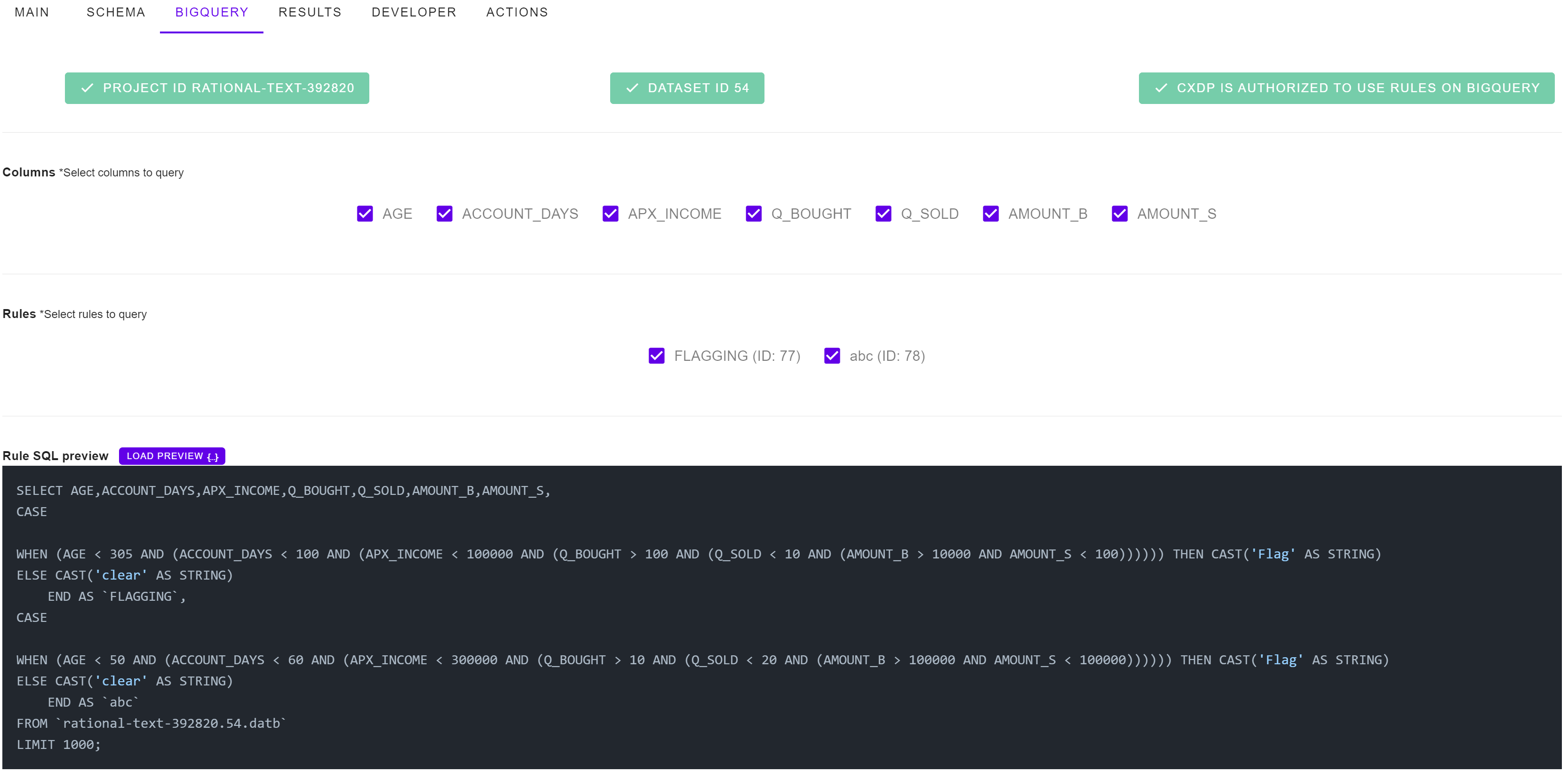
Nuestro servidor http procesa las solicitudes sobre la marcha mediante el uso de un pequeño módulo de Python que lee y aplica nuestra lógica directamente. Debido al desacoplamiento y la abstracción del sistema, también podríamos comunicar reglas a los clientes http directamente y procesar datos localmente en lugar de aplicar la regla de decisión a los datos del caso en el servidor http CXDP.
# Conclusiones
En esencia, CXDP es una plataforma low-code para crear reglas lógicas en esquemas de datos y, al mismo tiempo, una API que expone esas reglas y esquemas para que los desarrolladores los conecten con los proyectos o aplicaciones requeridos.
El problema clave que resuelve CXDP es el gasto excesivo de tiempo y esfuerzo en automatizar y gestionar el conocimiento dentro de las organizaciones y los procesos técnicos, ya que acelera y estandariza la forma en que los equipos técnicos interactúan con los expertos en el dominio.
CXDP promueve un método centralizado donde los equipos no técnicos pueden tener plena propiedad de la lógica empresarial aplicada en diferentes proyectos tecnológicos, mientras que los desarrolladores tienen una manera fácil y accesible de interactuar con la lógica crítica específica del dominio.
Para más información sobre este proyecto envíanos un email o mensaje directo, siempre estamos entusiasmados de compartir nuestras conclusiones e investigaciones.
© Cross Entropy Solutions, 2023.
Innovación a través de soluciones digitales.
info@crossentropy.solutions